Exploring Semantic Homogeneity in Unlabeled Data Clustering Using Large Language Models – Bashar FARES
Bashar FARES
Diplomová práce
Exploring Semantic Homogeneity in Unlabeled Data Clustering Using Large Language Models
Abstract:
This thesis investigates the topical clustering of unlabeled scientific text, leveraging various pre-trained large language models. The primary focus is on grouping the publication database at Deggendorf Institute of Technology (DIT) according to their main topics.Abstract:
This thesis investigates the topical clustering of unlabeled scientific text, leveraging various pre-trained large language models. The primary focus is on grouping the publication database at Deggendorf Institute of Technology (DIT) according to their main topics.
Jazyk práce: angličtina
Datum vytvoření / odevzdání či podání práce: 8. 2. 2024
Obhajoba závěrečné práce
- Vedoucí: prof. Dr. Andreas Fischer
Citační záznam
Citace dle ISO 690:
FARES, Bashar. \textit{Exploring Semantic Homogeneity in Unlabeled Data Clustering Using Large Language Models}. Online. Diplomová práce. České Budějovice: Jihočeská univerzita v Českých Budějovicích, Přírodovědecká fakulta. 2024. Dostupné z: https://theses.cz/id/zn85fp/.
Jak správně citovat práci
FARES, Bashar. Exploring Semantic Homogeneity in Unlabeled Data Clustering Using Large Language Models. České Budějovice, 2024. diplomová práce (Mgr.). JIHOČESKÁ UNIVERZITA V ČESKÝCH BUDĚJOVICÍCH. Přírodovědecká fakulta
Plný text práce
Obsah online archivu závěrečné práce
Zveřejněno v Theses:- světu
Jak jinak získat přístup k textu
Instituce archivující a zpřístupňující práci: JIHOČESKÁ UNIVERZITA V ČESKÝCH BUDĚJOVICÍCH, Přírodovědecká fakultaJIHOČESKÁ UNIVERZITA V ČESKÝCH BUDĚJOVICÍCH
Přírodovědecká fakultaMagisterský studijní program / obor:
Artificial Intelligence and Data Science / Artificial Intelligence and Data Science
Práce na příbuzné téma
-
Large Language Models as a tool for generating high-level features for text documents
Vojtěch Balek -
Large Language Models (LLMs): Examining the quality of generated text with task specific data
Michal Caninec -
Developing a Cybersecurity Domain Chatbot based on an Open Source Large Language Model
Shahrukh Azhar AHSAN -
Think Twice Before You Answer: Mitigating Biases of Question Answering Models
Lukáš Mikula
Název
Vložil
Vloženo
Práva
Složky
Soubory
Bulánová, L.
9. 2. 2024
-
Co je jinak přidání souboru
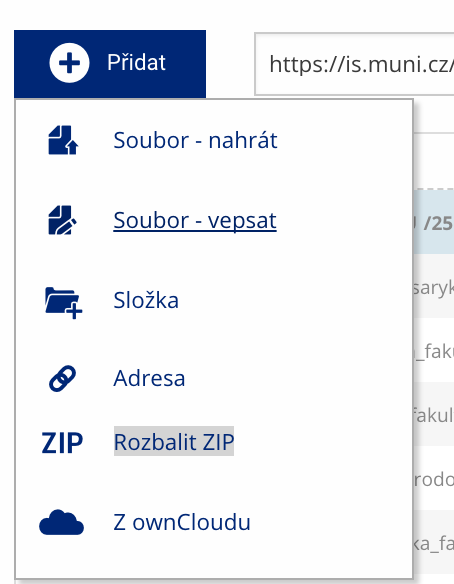 Soubor nebo složku lze nahrát pomocí tlačítka Přidat.
Soubor nebo složku lze nahrát pomocí tlačítka Přidat. -
Co je jinak další operace se soubory
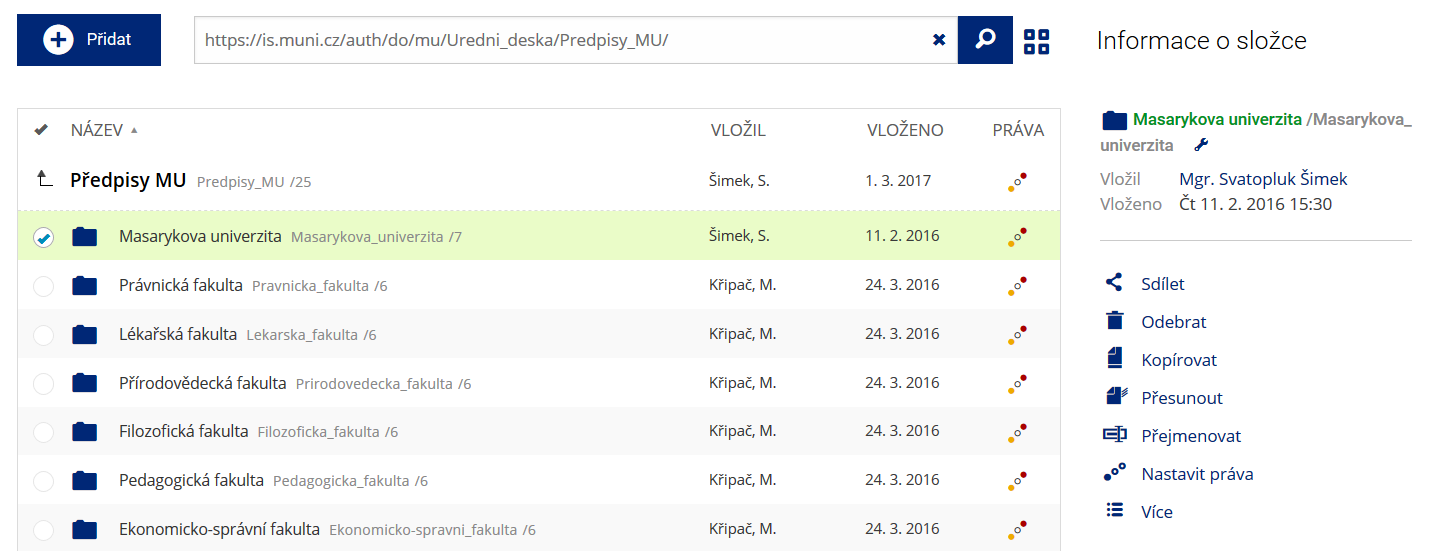 Podrobnosti lze zjistit označením příslušného řádku.
Podrobnosti lze zjistit označením příslušného řádku. -
Co je jinak pohled pro experty
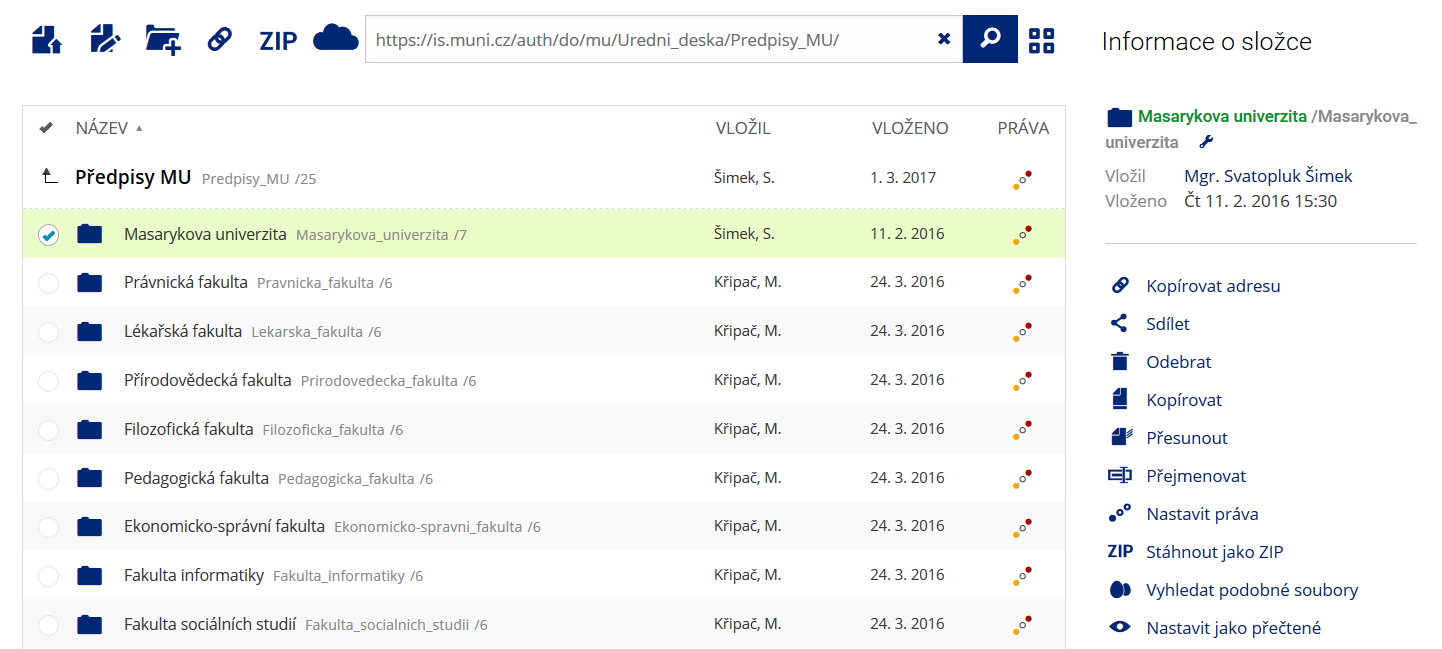 Pro častou práci je možné zvolit režim Více možností.
Pro častou práci je možné zvolit režim Více možností. -
Co je nové vyhledávání souborů
 Vyhledávaný výraz můžete zadat přímo do adresního řádku.
Vyhledávaný výraz můžete zadat přímo do adresního řádku. -
Co je nové rychlý přístup k souborům
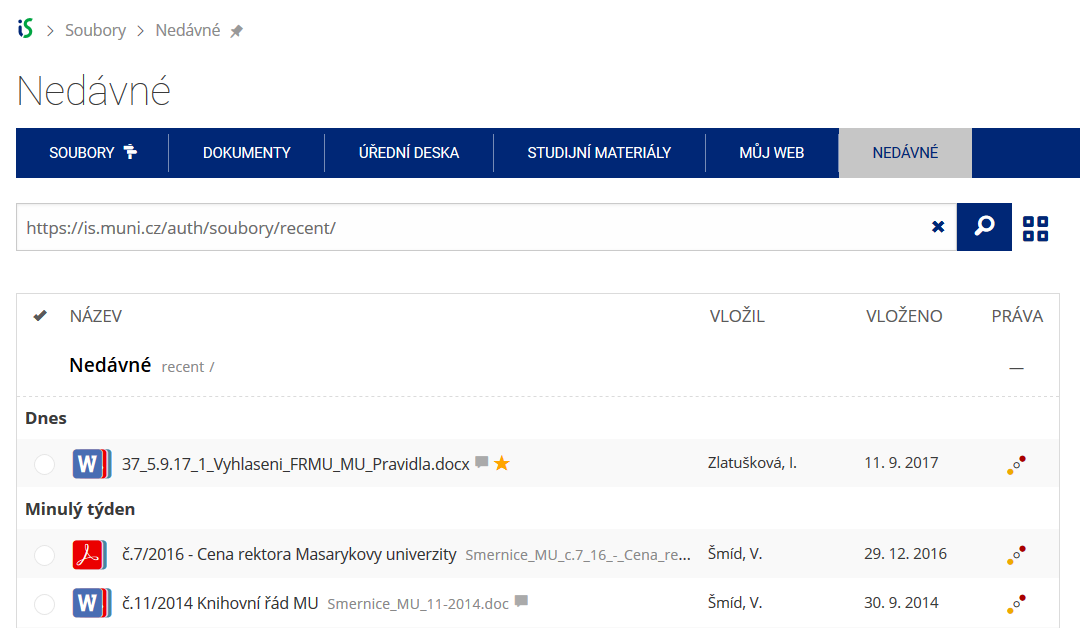 Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou.
Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou. -
Co se chystá
 Připravujeme další vylepšení pro mobilní zařízení.
Připravujeme další vylepšení pro mobilní zařízení.