Modelling and classification of large textual data – Bc. Vyacheslav Gatin
Bc. Vyacheslav Gatin
Diplomová práce
Modelling and classification of large textual data
Abstract:
The amount of data that the world creates has been increasing in geometrical progression (IBM, 2016), while textual data represents a big part of it. Manipulation with and classification of textual data are dealt with Natural Language Processing field of machine learning. This thesis explores the paradigm of machine learning, as being a key technique in modern data analysis and manipulation. Research …více
Jazyk práce: angličtina
Datum vytvoření / odevzdání či podání práce: 29. 11. 2018
Obhajoba závěrečné práce
- Vedoucí: Ing. Tomáš Hlavsa, Ph.D.
Citační záznam
Plný text práce
Obsah online archivu závěrečné práce
Zveřejněno v Theses:- světu
Jak jinak získat přístup k textu
Instituce archivující a zpřístupňující práci: Česká zemědělská univerzita v Praze, Provozně ekonomická fakultaČeská zemědělská univerzita v Praze
Provozně ekonomická fakultaMagisterský studijní program / obor:
Economics and Management / Economics and Management
Práce na příbuzné téma
-
Practical use of natural language processing in education technology
Dominik Hartinger -
Application of Natural language processing to enhance qualitative research used for marketing
Poj Nuangniyom Netsiri -
Scalability of Semantic Analysis in Natural Language Processing
Radim Řehůřek -
Application of machine learning to searching in unstructured data
Terézia Slanináková -
Indexing Data Using Machine Learning
Jakub Hanko -
Deployment of a federated machine learning architecture on oncological data
Martin Kadaši
Název
Vložil
Vloženo
Práva
-
Co je jinak přidání souboru
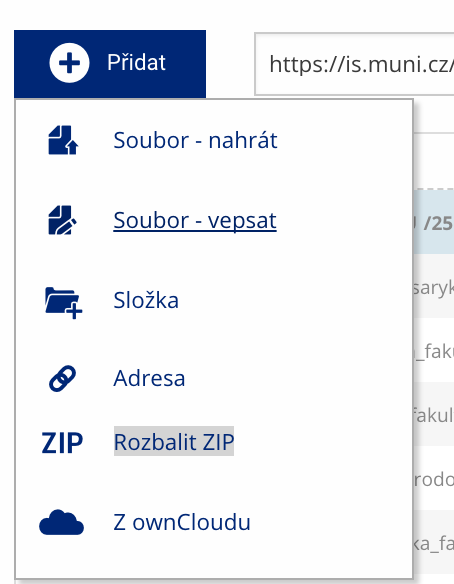 Soubor nebo složku lze nahrát pomocí tlačítka Přidat.
Soubor nebo složku lze nahrát pomocí tlačítka Přidat. -
Co je jinak další operace se soubory
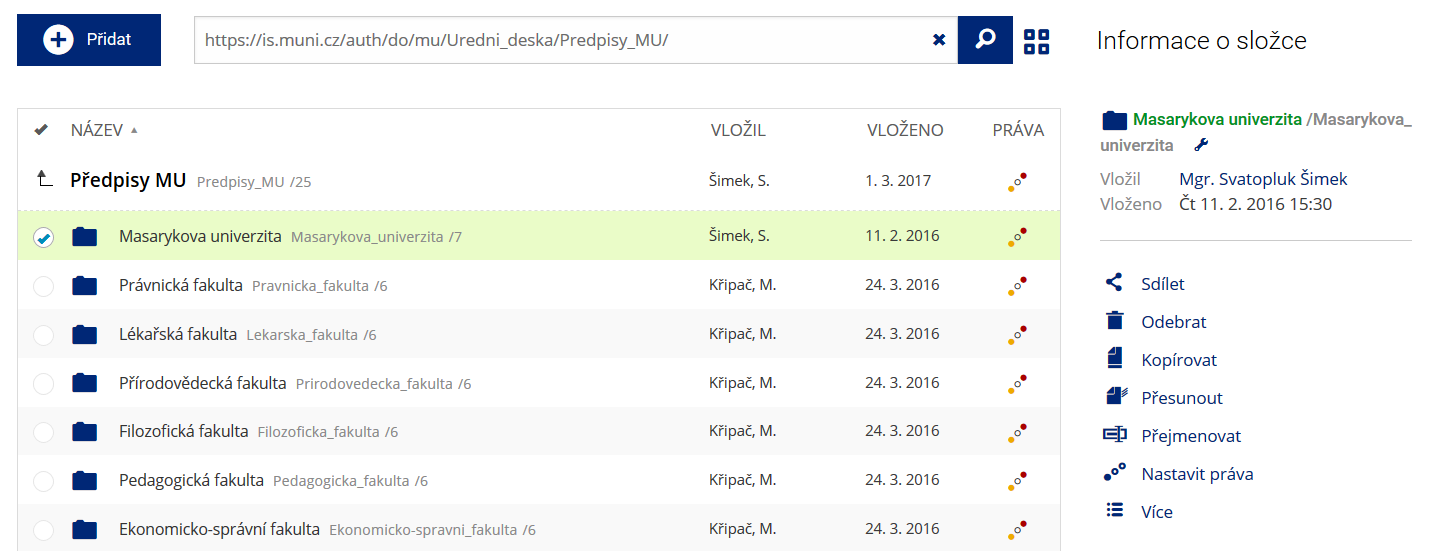 Podrobnosti lze zjistit označením příslušného řádku.
Podrobnosti lze zjistit označením příslušného řádku. -
Co je jinak pohled pro experty
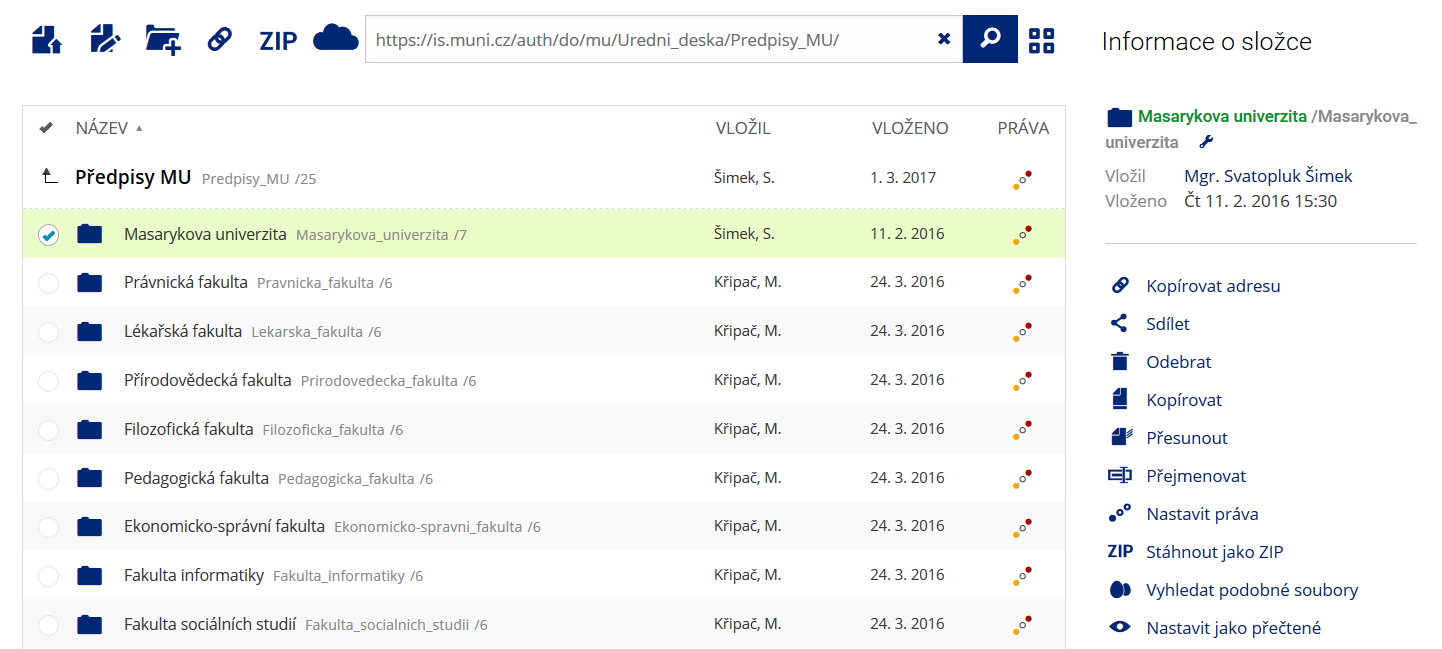 Pro častou práci je možné zvolit režim Více možností.
Pro častou práci je možné zvolit režim Více možností. -
Co je nové vyhledávání souborů
 Vyhledávaný výraz můžete zadat přímo do adresního řádku.
Vyhledávaný výraz můžete zadat přímo do adresního řádku. -
Co je nové rychlý přístup k souborům
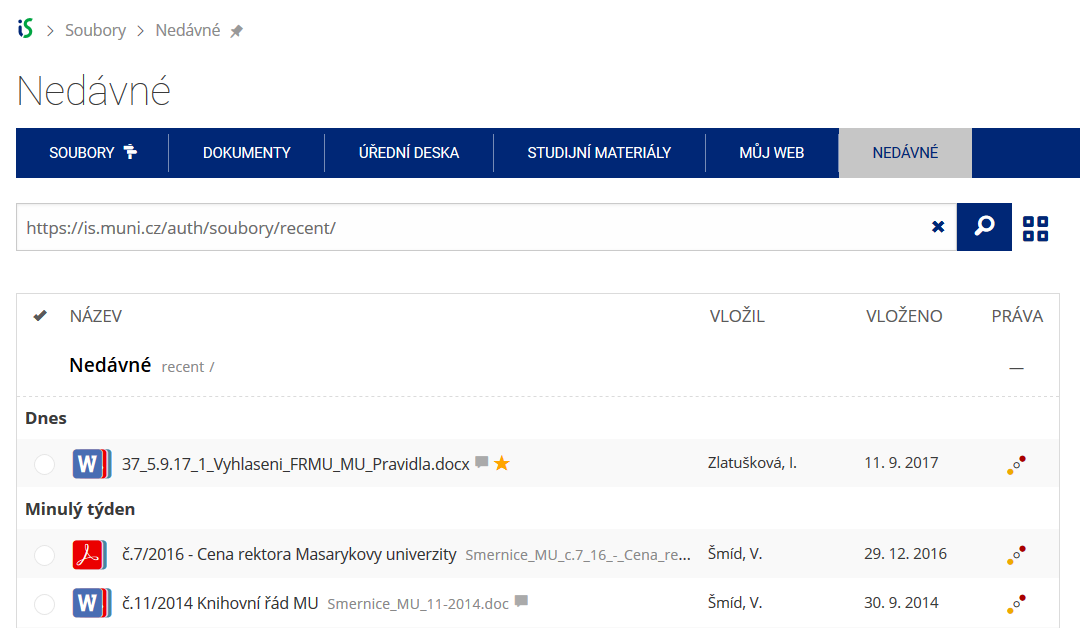 Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou.
Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou. -
Co se chystá
 Připravujeme další vylepšení pro mobilní zařízení.
Připravujeme další vylepšení pro mobilní zařízení.